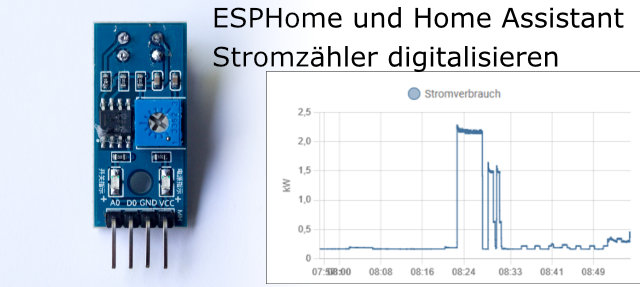
Digitalen Stromzähler auslesen mit SML und ESPHome
Die digitalen Stromzähler (offizielle Bezeichnung: Moderne Messeinrichtung) sind inzwischen weit verbreitet. Viele können in zwei Richtungen zählen, was bei der Benutzung eines Balkonkraftwerks von großer Bedeutung sein kann. Ich habe vor einiger Zeit beschrieben, wie ich mit dem Impulsausgang auf der Vorderseite des Stromzählers den aktuellen Verbrauch ablese. Diese Methode …